블로그
-
INSIGHT
AI트렌드에 개념더하기: AI 인공신경망
2024.03.15.
-

“I PROPOSE to consider the question, ‘Can machines think?’
By. A.M. Turing위 문장은 인공지능 연구의 아버지로 여겨지는 영국의 컴퓨터 과학자, 앨런 튜링의 논문 “Computing Machinery and Intelligence”의 첫번째 문장입니다.
튜링은 기계가 인간과 구분할 수 없도록 행동할 때, 그 기계를 ‘지능적’이라고 간주했는데요.
이 논문이 발간된 것이 1950년임을 감안하면, 기계에 Chat GPT와 같은 수준의 지능을 부여하기 위해서 70년 이상의 끊임없는 연구가 이어져왔다는 것을 알 수 있습니다.그렇다면, 우리는 어떻게 기계에 인간과 같은 지능을 부여할 수 있었을까요?
1. 사람의 머리 속에서 힌트를 얻다: 인공신경망오늘날 인공지능은 인간의 머리 속과 유사한 구조로 구성되었습니다.
인공신경망은 미국의 심리학자 프랑크 로젠블라트(Frank Rosenblatt)에 의해 1958년 시작되었다고 여겨지는데요. 그가 발명한 “퍼셉트론”(Perceptron)은 인간의 뇌가 작동하는 원리에 영감을 받아 고안되었습니다. 초기의 단순한 구조로 시작한 인공신경망은 많은 여정을 거쳐 발전해 왔습니다.
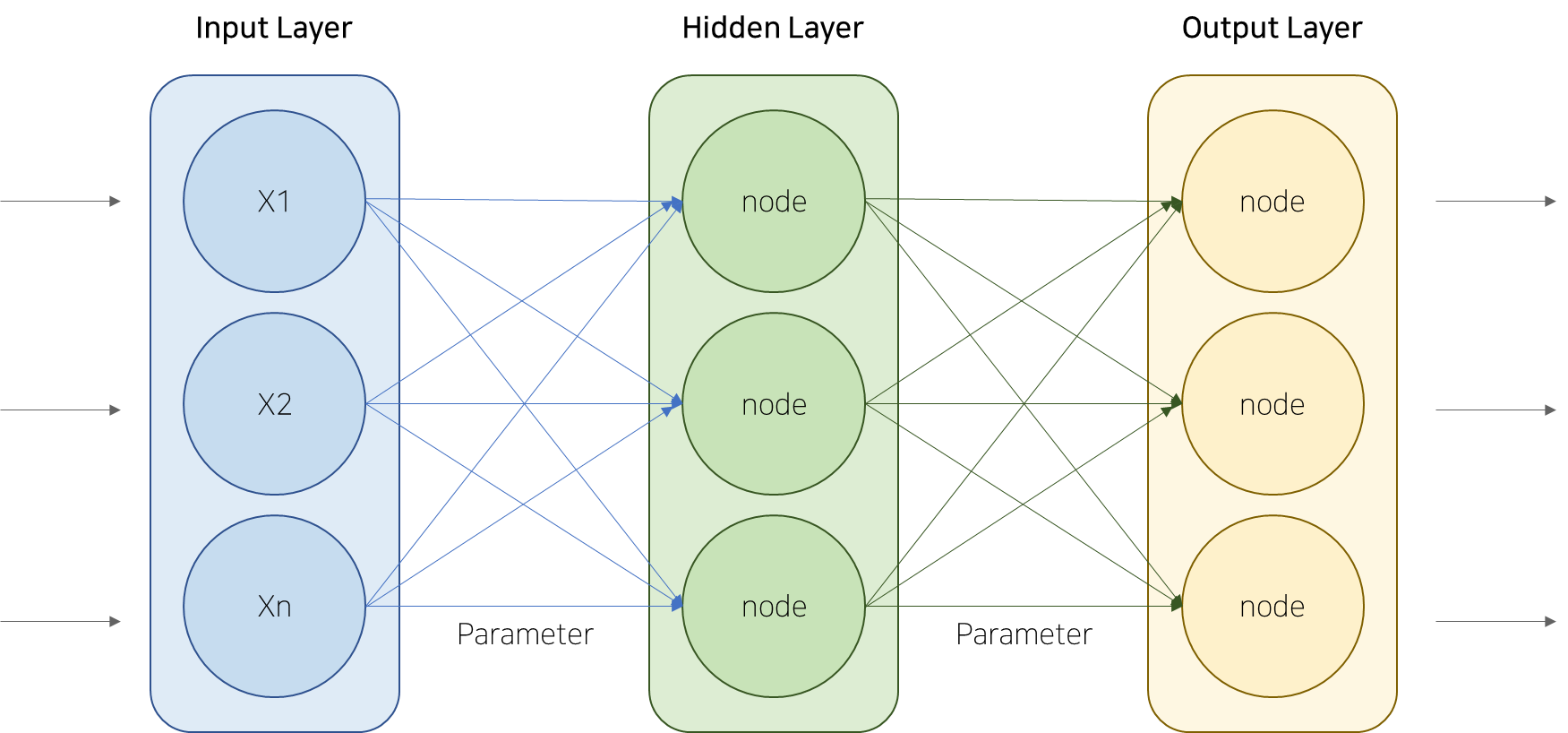
[그림1] 인공신경망 구조 (Artificial Neural Network, ANN)
오늘날의 인공지능을 구성하는 인공신경망은 신호를 전달하고 정보를 처리하는 역할을 담당하는 수백억 개의 뉴런이 모여 복잡한 네트워크를 형성하는 뇌와 같이, 정보 처리와 판단을 위한 수많은 노드(node)들로 구성되어 있습니다.
이러한 노드들이 연결되어 네트워크를 형성하는데요. 이는 다시 ‘입력층’, ‘은닉층’, ‘출력층’이라고 하는 세 개의 계층으로 나뉘어지며, 그 사이를 매개변수들이 연결합니다.
입력층 : 데이터/신호를 입력 받음
은닉층 : 입력층과 출력층 사이에 위치한 모든 층
출력층 : 처리된 데이터/신호를 기반으로 예측/결정함그렇다면, 인공신경망은 어떻게 작동할까요? 입력된 데이터는 노드를 통해 이동하면서, 활성화 함수를 거치게 되는데요. 활성화 함수는 다음과 같은 수식으로 이해할 수 있습니다.
Y = Activation Function ( X * W + b )
입력된 데이터(X)는 활성화 함수의 가중치(W)와 편향(b)에 따른 출력값으로 변환됩니다. 이 때, 출력된 값(Y)이 원하는 값과 일치하도록 하기 위해, 정해진 데이터셋(Data set, e.g.: [x1, y1])으로 훈련하는 과정을 통해 가중치와 편향을 조정합니다. 이 때, 언어모델이 학습하는 동안 조정되는 가중치(W)와 편향(b)이 인공신경망의 각 층을 연결하는 매개변수(Parameter)에 해당합니다.
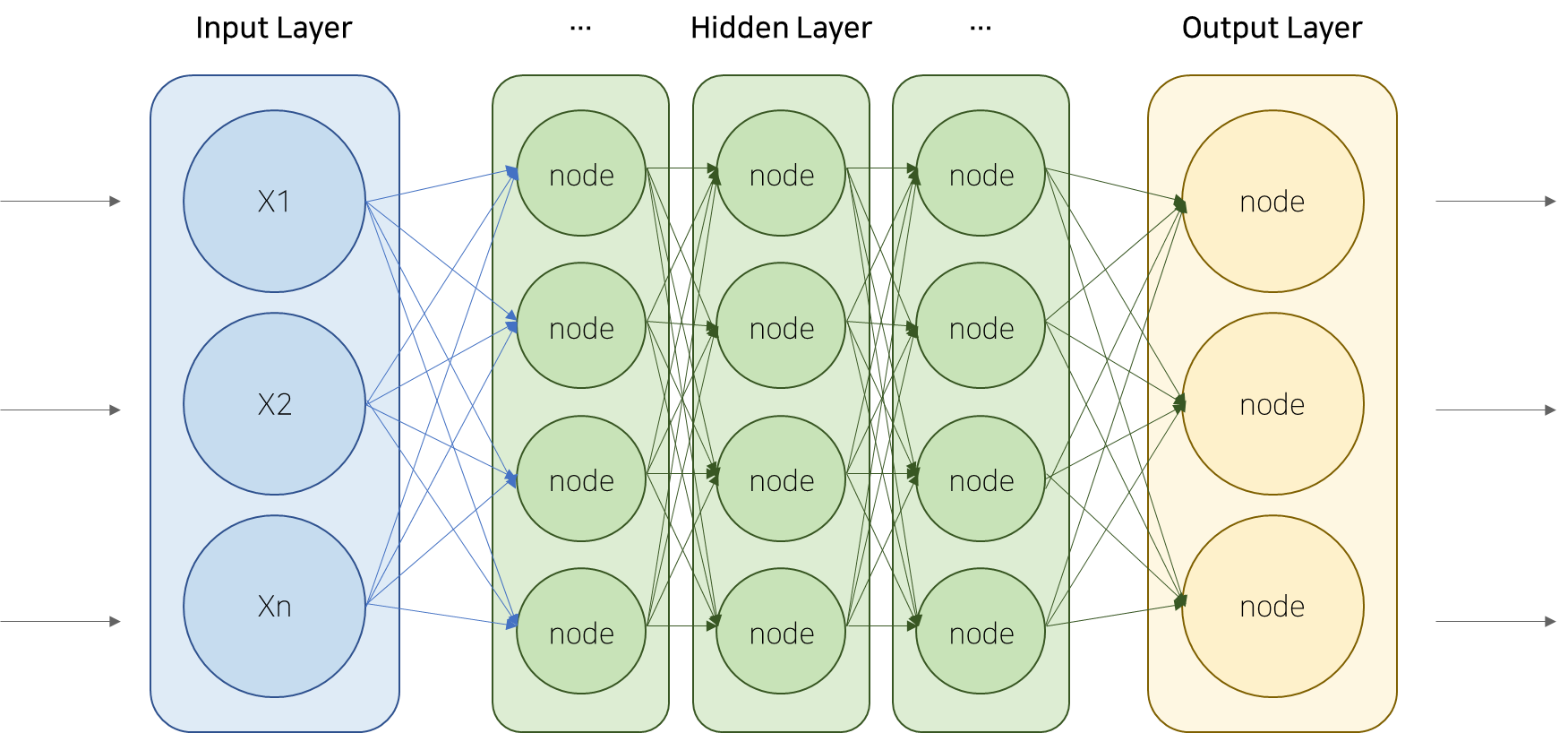
[그림2] 심층신경망 구조 (Deep Neural Network, DNN)
매개변수에 해당하는 가중치와 편향을 조절하는 것은 신경망 머신러닝에서 아주 중요한 부분인데요. 오류 역전파(Back-propagation of errors)는 출력된 결과값에 의도된 결과값과 오차가 발생하면 해당 오차만큼 앞으로 다시 전파해 가중치를 갱신하는 기술입니다.
2. 발전하는 인공신경망
더 빠르고 정확하게 판단하는 인공지능을 만들기 위한 기술 연구는 계속되고 있습니다.
한 예로, 생성적 적대 신경망 (Generative Adversarial Network, GAN)은 2014년에 이안 굿펠로우(Ian Goodfellow)와 그의 동료들에 의해 처음 소개된 딥러닝 기술인데요.
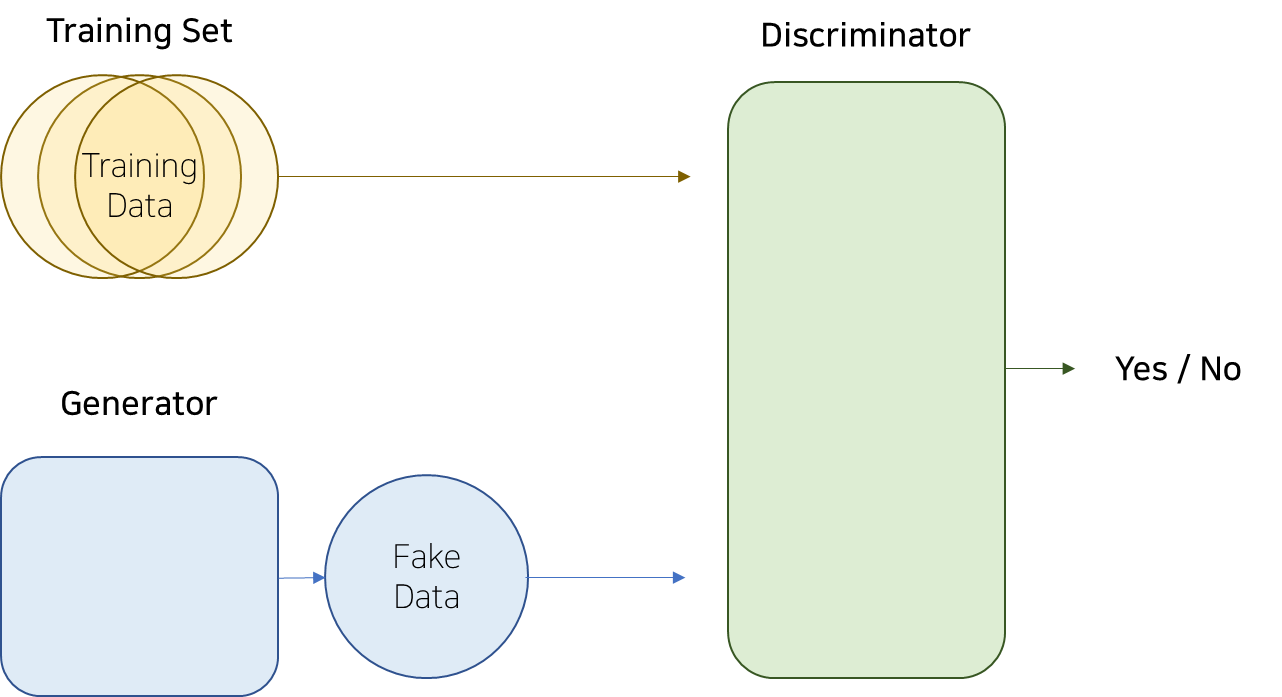
[그림3] 생성적 적대 신경망 (Generative Adversarial Network, GAN)
GAN은 기본적으로 생성자(Generator), 판별자(Discriminator)로 구성되며, 두 개의 네트워크를 적대적으로 학습하여 실제 데이터와 유사한 데이터를 생성하는 모델입니다.
생성자 (Generator): 무작위의 데이터로부터 실제 데이터와 유사한 가짜 데이터를 생성
판별자 (Discriminator): 생성자에서 만들어진 가짜 데이터와 실제 데이터를 구별하는 능력을 키움GAN의 작동 원리는 다음과 같습니다.
| 학습 초기
- 생성자는 무작위로 생성한 가짜 데이터를 판별자에게 제시하고, 판별자는 이를 실제 데이터와 구별하기 위해 학습합니다.
- 초기에는 생성자가 부족한 가짜 데이터를 생성하고 판별자는 이를 쉽게 식별합니다.| 경쟁과 학습
- 경쟁이 계속되면서 생성자는 더욱 실제와 유사한 데이터를 만들어내려 노력하고, 판별자는 더욱 정교한 판단 능력을 키우려고 합니다.
- 이 과정에서 생성자와 판별자는 서로의 능력을 끊임없이 향상시키는 경쟁관계에 놓이게 됩니다.| 수렴
- 최적의 상태에 도달하면 생성자가 만들어내는 가짜 데이터는 실제 데이터와 거의 구별이 어려워지며, 판별자는 최대한 양립할 수 있게 됩니다.|
이처럼 빠르게 발전하는 인공지능 기술은 창조적인 예술 작품부터 실제 데이터의 확장까지 다양한 분야에서 활용되며, 그 가능성은 계속해서 확장되고 있습니다. 인공지능 분야의 다양한 발전들은 앞으로도 기술과 연구의 진보를 통해 사용자의 삶에 더 놀라운 변화를 만들어 나갈 것으로 기대됩니다.
-
Reference
A. M. TURING, I.—COMPUTING MACHINERY AND INTELLIGENCE, Mind, Volume LIX, Issue 236, October 1950, Pages 433–460, https://doi.org/10.1093/mind/LIX.236.433IBM, “What is a neural network?”
https://www.ibm.com/topics/neural-networksAlexx Kay, COMPUTERWORLD (2001.02.12), “Artificial Neural Networks”
https://www.computerworld.com/article/2591759/artificial-neural-networks.html추형석 연구원, SPRi 소프트웨어정책연구소 (2017.09.29), “적대적 생성신경망(Generative Adversarial Network)의 소개와 활용 현황”
https://www.spri.kr/posts/view/21883?code=industry_trend*본 콘텐츠는 Chat GPT를 활용해 일부 작성되었습니다.